
Une Importation peut être créée de deux manières différentes :
- À partir du menu volant de l'entrée Échange de données, dans la barre de navigation de gauche. Cliquez sur le bouton Nouveau et sélectionnez Importation de données dans la liste déroulante.
- Dans la page de démarrage Importations/Exportations, sélectionnez Nouveau > Importation de données. Un assistant vous guide tout au long du processus de création et de configuration de l'importation.
Créer une importation des données programmée
- Définir les propriétés
- Définir les options de programmation et de notification
- Notifications
- Configurer le planificateur (Optionnel)
Définir les options d'importation
- Sélectionner la liste
- Définir les Options d'importation
- Définir la source
- Définir les Options du fichier
Définir la correspondance des champs
Créer une importation des données programmée
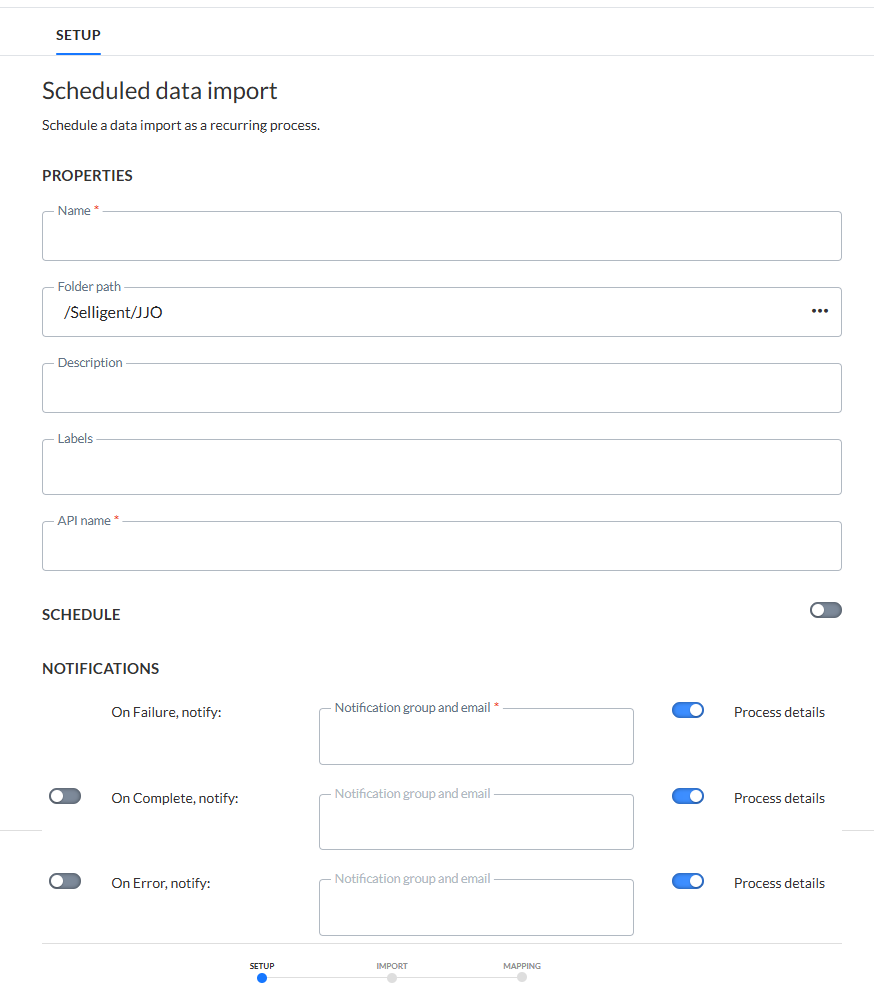
Définir les propriétés
Définissez le chemin du dossier pour l'importation. Il s'agit de l'emplacement dans la structure de dossiers où l'importation est stocké.
Saisissez le nom et la description de cette importation.
Définissez le Nom de l'API pour l'importation. Ce nom est utilisé lorsque l'importation est exécutée via l'API. Par défaut, le nom de l'API est complété par le nom donné à cette importation.
Libellé de l'actif — Le(s) libellé(s) attribué(s) à cet actif. Sélectionnez un ou plusieurs libellés dans la liste déroulante. (Ces libellés sont créés dans le module Configuration Admin.) Les utilisateurs disposant des autorisations d'accès appropriées peuvent également créer de nouveaux libellés en saisissant leur nouvelle valeur dans le champ.
Définir les options de programmation et de notification
La section Programmation permet de définir la période de validité de l'importation, ainsi que son occurrence d'exécution.
Pour programmer votre importation, activez cette option et définissez-en la programmation.
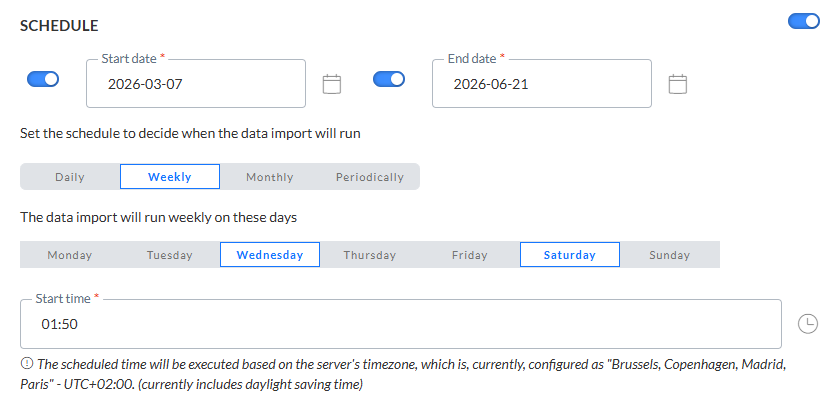
Dates de début et de fin — Vous pouvez définir une date de début et/ou une date de fin pour l'importation. Votre importation doit par exemple être lancée immédiatement, mais être exécutée indéfiniment.
Périodicité — Permet d'indiquer quand l'importation doit être exécutée :
- Tous les jours — Permet de sélectionner les heures de la journée auxquelles l'importation doit être exécutée. Vous pouvez en sélectionner plusieurs.
- Toutes les semaines — Permet de sélectionner le jour de la semaine auquel l'importation doit être exécutée. L'importation peut être exécutée plusieurs fois par semaine. Vous pouvez également définir l'heure de début.
- Tous les mois — Permet de sélectionner les jours du mois auxquels l'importation doit être exécutée. Vous pouvez également sélectionner l'heure de la journée à laquelle l'importation doit être lancée.
- Périodiquement — Permet de définir la récurrence de l'importation, exprimée en minutes. Par exemple, l'importation est exécutée toutes les 10 minutes.
Remarque : L'heure de programmation sera exécutée en fonction du fuseau horaire du serveur. Le fuseau horaire du serveur actuellement configuré est mentionné à côté de l'icône d'information.
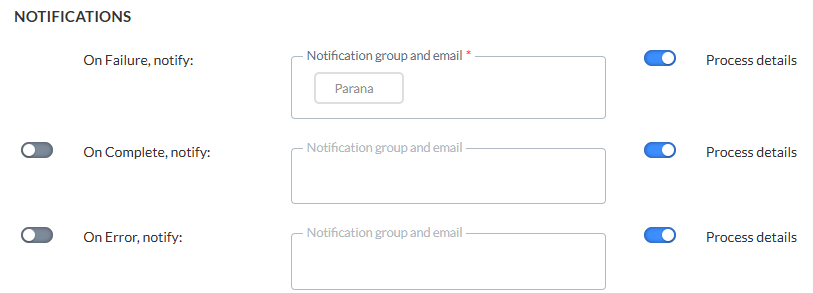
Notifications
Un message peut être envoyé :
- * OnFailure — Lorsque le processus échoue. Au moins une adresse e-mail est obligatoire.
- OnComplete — Lorsque la tâche est terminée avec succès.
- OnError — Lorsque la tâche est terminée avec des erreurs (le travail a été terminé, mais une ou plusieurs tâches ont généré des erreurs/exceptions).
- On No file — Lorsqu'aucun fichier n'a pu être trouvé.
Les détails de la procédure peuvent être inclus dans le message. En outre, l'instance sur laquelle le problème est survenu est incluse dans l'objet du message.
Pour activer l'option, il suffit d'activer la bascule à gauche et de saisir une ou plusieurs adresses e-mail. (Les adresses e-mail doivent être séparées par un point-virgule.) Vous pouvez également sélectionner un groupe de notifications. Ces groupes de notifications sont créés dans le module Configuration Admin.
Remarque: il est obligatoire de définir un ou plusieurs groupes de notifications/adresses e-mail en cas d'échec de l'import. Les autres notifications (achèvement ou erreurs) sont facultatives.
Lorsque vous avez terminé, cliquez sur Suivant.
Configurer le planificateur (Optionnel)
Remarque: La section Planificateur n'est visible que si des planificateurs sont configurés sur votre environnement. Par défaut, il y a 1 planificateur, auquel cas cette section n'est pas affichée car ce planificateur par défaut est utilisé. S'il existe plus d'un planificateur configuré, vous avez accès à la section Planificateur.
Lorsque plusieurs tâches, importations ou exportations sont exécutées, il pourrait se révéler judicieux d'utiliser un planificateur différent afin de s'assurer que les tâches dont l'exécution est longue n'interfèrent pas avec les tâches dont l'exécution est plus courte. La configuration d'un planificateur est facultative. Si vous conservez le planificateur par défaut, toutes les tâches/exportations/importations seront exécutées, mais si l'une des tâches est plus longue, la tâche plus courte ne sera exécutée que lorsque cette tâche plus longue sera terminée.

Vous pouvez choisir entre 3 planificateurs différents : le planificateur par défaut, le planificateur personnalisé 1 et le planificateur personnalisé 2. En sélectionnant des planificateurs différents pour vos tâches, ces dernières vont s'exécuter en parallèle, sans interférer l'une avec l'autre. Ce qui signifie que si certaines tâches sont plus longues à exécuter, il pourrait se révéler judicieux de les exécuter sur un planificateur différent.
Définir les options d'importation
Sélectionner la liste
Liste — Dans le menu déroulant, sélectionnez la liste dans laquelle les fiches doivent être importées. Il peut s'agir d'une la liste d'audiences, d'une liste de données, d'une liste d'options, d'une liste de sélection de données ou d'événements personnalisés.
Pour effectuer une importation dans une liste d'événements personnalisés, sélectionnez d'abord une liste d'audiences. La fonction bascule permet d'activer l'importation dans les événements personnalisés. Tous les événements personnalisés liés à la liste d'audiences sélectionnée sont répertoriés dans le menu déroulant en dessous de la fonction bascule :
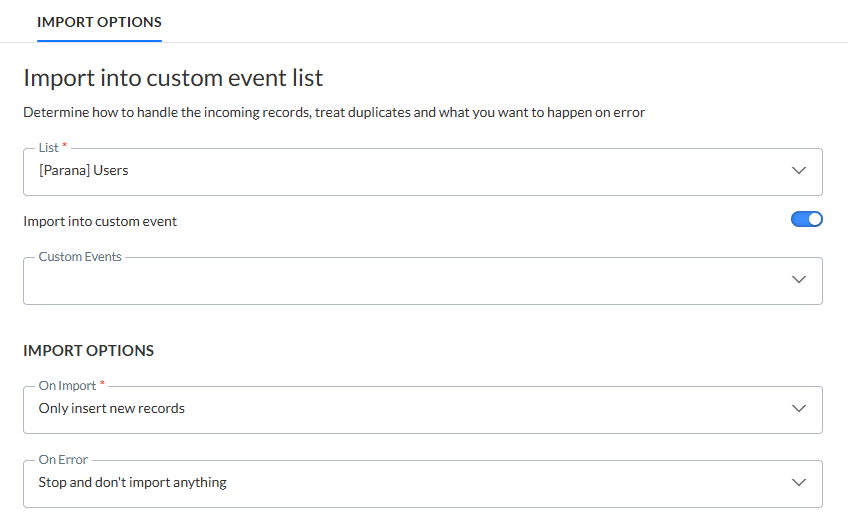
Remarque: Lors de la modification d'une liste après qu’une mise en correspondance des champs ait été définie, une notification s’affiche indiquant que toutes les mises en correspondance des colonnes seront perdues si vous continuez. Vous pouvez annuler les modifications en cliquant sur le lien Annuler correspondant. Cliquez sur le lien pour réinitialiser l’audience sur celle précédemment sélectionnée.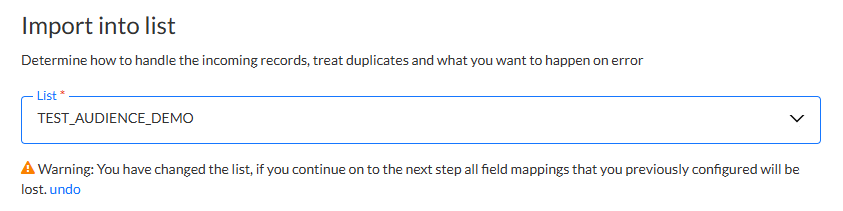
Définir les Options d'importation
Lorsque vous importez des données dans une liste ou un segment qui contient déjà des fiches, vous devez définir le résultat de l'importation.
À l'importation
- Insérer les nouvelles fiches et mettre à jour les fiches existantes (uniquement pour les importations dans des listes, et non dans des segments) .Pour les importations dans les événements personnalisés, seules les nouvelles fiches peuvent être ajoutées. Les anciennes fiches ne peuvent pas être mises à jour.
- Insérer seulement les nouvelles fiches — Les fiches existantes ne sont pas mises à jour, seules de nouvelles fiches sont créées.
- Uniquement mettre à jour les fiches existantes — Aucune nouvelle fiche n'est insérée (uniquement pour les importations dans des listes, et non dans des segments)
- Supprimer les fiches existantes — Lorsqu'une correspondance avec la fiche d'une liste a été établie, la fiche est supprimée. Aucune autre fiche n'est mise à jour ou insérée.
Remarque: L'option Supprimer les fiches existantes ne peut pas être utilisée en combinaison avec une importation dans une liste liée 1:1, ni en cas de transformation des valeurs via la recherche inverse.
Au dédoublonnage des données (uniquement pour les listes, pas pour les segments ni les événements personnalisés.)
- Importer la première correspondance — Si des doublons sont trouvés, la première fiche correspondant à une fiche existante est importée. Toutes les fiches suivantes qui correspondent à cette fiche existante ne sont pas importées.
- Importer la dernière correspondance — Si des doublons sont trouvés, la dernière fiche correspondant à une fiche existante est importée.
En cas d'erreur — Définit le comportement du processus d'importation lorsqu'une fiche erronée est détectée. Vous disposez des options suivantes :
- Arrêter et ne rien importer — Lorsqu'un problème survient dans un fichier, cette option interrompt le traitement du fichier en cours et génère une notification à l'adresse OnFailure. Les fichiers précédents peuvent avoir été importés avec succès au cours de cette tâche.
- Poursuivre l'importation — Ignore la fiche erronée et poursuit l'importation, en générant éventuellement une notification à l'adresse OnComplete si celle-ci est définie dans les notifications.
Exemples d'erreurs :
- Nombre insuffisant de colonnes (attendu 5, détecté 3)
- Données trop longues pour le type de données Liste (55 caractères pour un champ de texte de 50 caractères)
- Types de données mal assortis (texte alors qu'un nombre est attendu)
- Données absurdes (ex. 1975-13-37)
Remarque: Si un fichier vide est détecté, la routine d'importation de données s'interrompt, même si l'option Continuer l'importation est sélectionnée.
Exemple:
A.csv (10 bonnes fiches)
B.csv (10 bonnes fiches)
C.csv (10 fiches dont les fiches 5 et 7 sont corrompues)
D.csv (10 bonnes fiches)
Si l'option Arrêter et ne rien importer est activée, 20 fiches des fichiers A et B seront traitées. Les 4 premières fiches du fichier C ne seront pas traitées et le fichier D ne sera pas traité non plus.
Si l'option Continuer l'importation est activée, toutes les fiches de tous les fichiers seront traités, à l'exception des 2 fiches corrompues du fichier C.
Remarque technique: Les fichiers sont traités dans l'ordre lexical (eg. 1, 10, 100, 2, 33, 4, 500 ). Si l'ordre de traitement des fichiers est important pour vous, nous vous recommandons d'utiliser une date ou un numéro de séquence dans le nom du fichier. De même, si l'ordre de traitement est important, nous vous recommandons également de ne pas utiliser l'option Continuer l'importation.
Définir la source
Emplacement — La liste des emplacements possibles comprend : Référentiel, URL autorisée, URL publique, Azure Blob Storage, Amazon S3 Storage, Google Cloud Storage, FTP, SFTP, FTPS. Les paramètres à saisir dépendent du type d’emplacement sélectionné. L'utilisateur peut sélectionner un sous-dossier pour stocker le fichier. Le type de fichier est séparé par défaut par ';'.
- Référentiel — Le serveur sur lequel la procédure est effectuée contient un système de fichiers local comprenant déjà deux dossiers : Data In et Données Campaign. Vous pouvez sélectionner un sous-dossier dans lequel récupérer le fichier d'importation.
- URL publique — Fournissez l'URL. Accessible sans informations de connexion ni mot de passe et supportant HTTP ou HTTPS.
- URL autorisée — Saisissez l'URL et le nom d'utilisateur, ainsi que le mot de passe permettant de s'y connecter. Ne prend en charge que le protocole HTTPS.
- Azure Blob Storage — Saisissez la chaîne de connexion (vous pouvez activer ou désactiver l’affichage de la chaîne en cliquant sur l’icône Œil) et le conteneur, ainsi qu’un sous-dossier facultatif. (*)
- Amazon S3 Storage — Saisissez l’ID de la clé d’accès et la clé d’accès secrète (vous pouvez activer ou désactiver l’affichage des deux chaînes en cliquant sur l’icône Œil), le nom du compartiment, le code du point de terminaison de la région et un sous-dossier facultatif. (*)
- Google Cloud Storage — Saisissez le type, l’ID projet, l’ID de la clé privée et la clé privée (vous pouvez activer ou désactiver l’affichage des deux chaînes en cliquant sur l’icône Œil), l’e-mail client, l’ID client, l’URI d'authentification, l’URI du token, l’URL du certificat X509 du fournisseur d'authentification, l’URL du certificat X509 du client, le nom du compartiment et un sous-dossier facultatif. (*)
* Remarque: Vous trouverez ici des détails sur la façon de configurer le stockage dans le Cloud.
- Prédéfini — Lorsque vous sélectionnez cette option, le champ 'Moyen de transport prédéfini' s'affiche ; il vous permet de sélectionner un moyen dans une liste de moyens prédéfinis. Ces moyens sont déjà configurés dans le module Admin Configuration et liés à votre Unité commerciale. Lorsque vous sélectionnez un paramètre, tous les paramètres correspondants sont utilisés.
- FTPS, FTPS implicite, SFTP — Indiquez dans cette boîte de dialogue le nom du serveur, ainsi que le nom d'utilisateur et le mot de passe permettant de s'y connecter. Vous pouvez sélectionner un sous-dossier sur le serveur. Un sous-dossier est indiqué par défaut.
Remarque: Lorsqu’une importation de données a été exécutée, le fichier est automatiquement supprimé du FTP.
Filtre de fichiers — Par défaut, défini sur *. Ce champ permet de filtrer les fichiers sur le emplacement sélectionné, uniquement pour ceux répondant à ce critère de filtrage (par ex. : *.txt)
Authentification par clé privée
Pour SFTP, outre l'utilisation d'un mot de passe pour s'authentifier lors de la connexion au serveur, il est possible d'utiliser une clé privée:
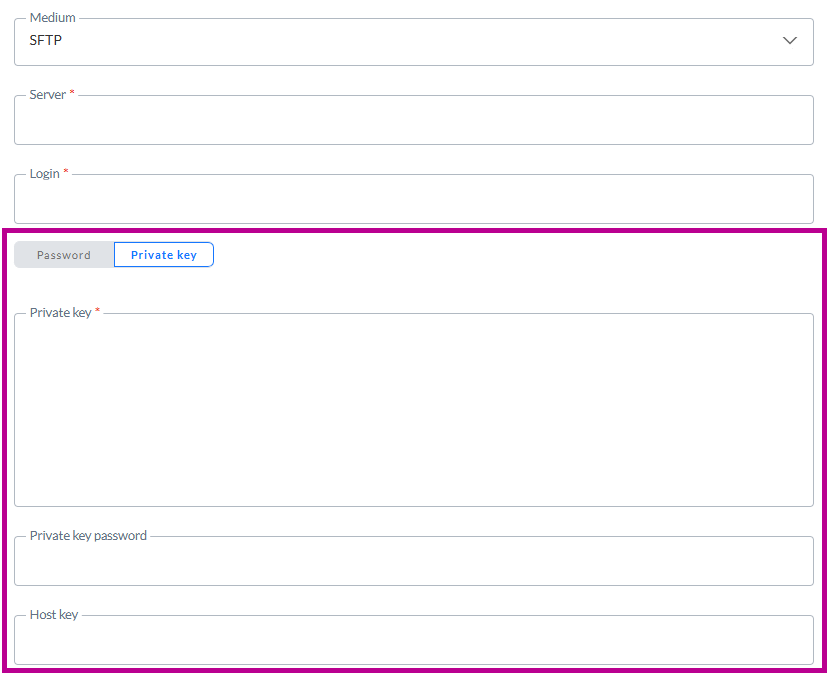
Un curseur permet de choisir entre Mot de passe et Clé privée.
Lorsque l'option Clé privée est sélectionnée, vous pouvez saisir (ou coller) les données de la clé privée dans le champ Clé privée.
Si la clé privée requiert un mot de passe (comme c'est le cas sur certains serveurs), vous pouvez saisir le mot de passe dans le champ Mot de passe de la clé privée. Ce champ est facultatif.
Remarque: Les données des deux champs (clé privée et mot de passe de la clé privée) sont cryptées et stockées dans la base de données et ne sont utilisées que lors du transfert des fichiers.
La clé d'hôte est un champ facultatif qui peut être utilisé comme étape de vérification supplémentaire pour s'assurer que vous vous connectez au bon serveur.
Remarque:
Lors de l'enregistrement de la [Tâche d'importation/Importation de données/Tâche d'exportation/Exportation de données/Emplacement] :
- Le contenu du champ de la clé privée est vidé (pour des raisons de sécurité).
- L'intitulé du champ Clé privée est mis à jour et devient Spécifier une nouvelle clé privée pour mettre à jour la clé privée existante.
- Le contenu du champ Mot de passe de la clé privée est vidé (pour des raisons de sécurité).
- L'intitulé du champ Mot de passe de la clé privée est mis à jour et devient Spécifier un nouveau mot de passe de la clé privée pour mettre à jour le mot de passe de la clé privée existante.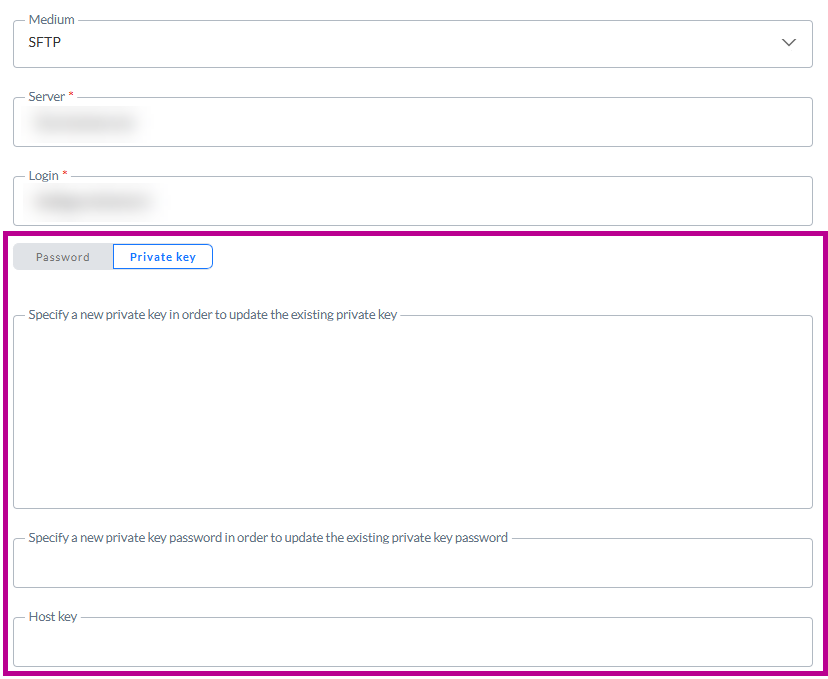
Définir les Options du fichier

Vous pouvez choisir entre :
- Délimité — Les fichiers délimités utilisent des virgules, des points-virgules, des barres verticales ou des tabulations comme délimiteur de colonnes
- Excel (XLS) — Un fichier Excel avec ou sans en-tête de ligne peut être utilisé comme fichier d'importation. XLS et XLSX peuvent être utilisés.
- RSS — Le nœud racine du fichier RSS doit être fourni
Delimited
Cliquez sur l'icône Crayon pour accéder à la boîte de dialogue Options du fichier.
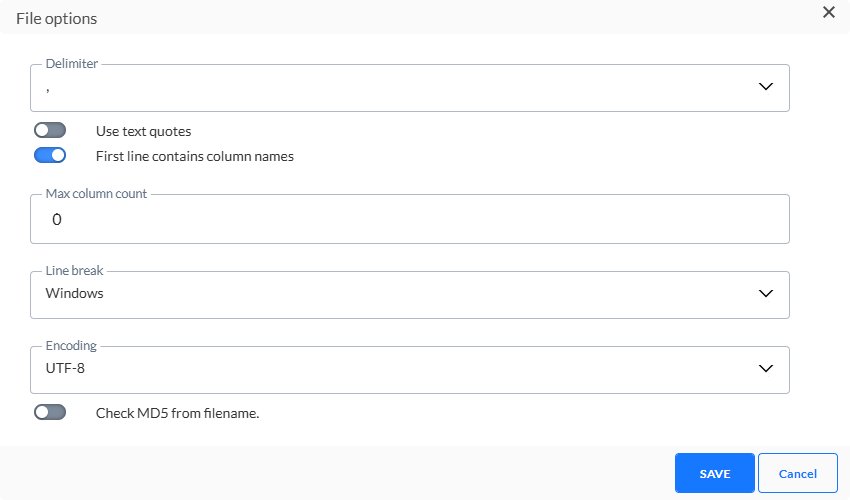
- Le délimiteur de fichier peut être défini sur : deux-points, point-virgule, tabulation ou barre verticale. Par défaut, le délimiteur est défini sur ';'.
- Il est possible de mettre le texte entre guillemets doubles. Activez cette option, le cas échéant.Si tel est le cas, toutes les données alphanumériques sont incluses dans les guillemets. Ainsi, un champ contenant le caractère délimiteur ne sera pas interprété comme une colonne supplémentaire. Notez toutefois que les sauts de ligne ne sont pas pris en charge.
- Vous pouvez également définir la première ligne comme étant celle contenant les noms des colonnes. Cette option est sélectionnée par défaut.
- Définissez le type d'encodage à appliquer au fichier. Cliquez sur la liste déroulante pour accéder à la liste étendue des mécanismes d'encodage.
- Nombre max de colonnes — Nombre maximum de colonnes autorisées dans le fichier.
- Saut de ligne — Permet de définir le saut de ligne sur Windows ou Unix. Windows utilise le retour chariot et le saut de ligne ("\r\n") en fin de ligne, où Unix utilise uniquement le saut de ligne ("\n").
- Encodage — Permet de définir le type d'encodage à appliquer au fichier. Cliquez sur la liste déroulante pour accéder à la liste étendue des mécanismes d'encodage.
- Vérifier MD5 à partir du nom du fichier — Cette option permet de revérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
Excel (XLS)
Cliquez sur l'icône Crayon pour accéder à la boîte de dialogue Options du fichier.
Nom de feuille — Nom de la feuille du fichier .xls qui est le sujet de l'importation. Lorsqu'il y a plusieurs feuilles de calcul, seule la feuille de calcul nommée est traitée, toutes les autres feuilles de calcul sont ignorées. S'il y a plusieurs feuilles de calcul à traiter, elles doivent être traitées comme des fichiers XLSX individuels, car une seule feuille de calcul peut être importée à la fois.
La première ligne contient les noms des colonnes — Sélectionnez cette option si la ligne supérieure de votre feuille contient les noms des colonnes.
Lignes à passer — Indiquez le nombre de lignes du fichier à exclure.
Encodage — Permet de définir le type d'encodage à appliquer au fichier. À partir du menu déroulant, vous avez accès à une liste complète de mécanismes de codage. De plus, l'option Vérifier MD5 à partir du nom du fichier est utilisée pour vérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
RSS
Cliquez sur l'icône Crayon pour accéder à la boîte de dialogue Options du fichier.
Nœud racine (facultatif) — Nœud racine dont tous les nœuds enfants sont récupérés. Si le nœud racine n'est pas configuré, le Xpath par défaut dans lequel les données sont attendues est le nœud Channel. Si le nœud racine est configuré, vous pouvez utiliser ce nom.
Remarque: Tous les éléments <item> et leur contenu à l'intérieur du nœud racine (par exemple, <channel>) peuvent être importés.
Si d'autres éléments apparaissent directement sous l'élément racine (au même niveau que les éléments <item>), ils ne seront pas importés.
Exemple 1 — Si nous ne configurons pas de nœud racine, le nœud 'channel' de ce fichier RSS sera utilisé comme racine par défaut (l'article et ses détails seront importés) :
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</channel>
</rss>Exemple 2 — Si nous configurons un élément "customrss" comme nœud racine, il sera utilisé comme racine dans le fichier RSS suivant (l'article et ses détails seront importés) :
<?xml version="1.0" ?>
<rss version="2.0">
<customrss>
<item>
<title>News of today</title>
<link>https://www.xul.fr/en-xml-rss.html</link>
<description>RSS item 1</description>
<name>Siyashree</name>
</item>
</customrss>
</rss>Encodage — Permet de définir le type d'encodage à appliquer au fichier. Cliquez sur la liste déroulante pour accéder à la liste étendue des mécanismes d'encodage.
Vérifier MD5 à partir du nom du fichier — Cette option permet de revérifier le contenu du fichier. Cette clé MD5 est ajoutée au nom du fichier et est créée sur la base du contenu du fichier. Si cette option est activée, la clé MD5 est vérifiée par rapport au contenu du fichier et active la détection de modifications dans le fichier.
Remarque: Lors de l'utilisation de fichiers RSS, Media RSS* est pris en charge par défaut.
* Qu'est-ce que Media RSS ? Il s'agit d'une extension RSS qui apporte plusieurs améliorations aux annexes RSS et qui est utilisée pour la syndication de fichiers multimédias dans les flux RSS. Elle a été conçue à l'origine par Yahoo! et la communauté Media RSS en 2004, mais en 2009, son développement a été confié au RSS Advisory Board.
Veuillez consulter https://www.rssboard.org/media-rss pour plus d'informations.
Exemple de fichier RSS contenant des médias (MRSS):
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
<title>The latest video from artist XYZ</title>
<link>http://www.foo.com/item1.htm</link>
<artist>XYZ</artist>
<media:content url="http://www.foo.com/movie.mov" type="video/quicktime" />
<media:keywords><![CDATA[XYZ, album, song, year]]></media:keywords>
<media:thumbnail url="http://www.foo.com/XYZ.jpg" width="98" height="98"></media:thumbnail>
</item>
</channel>
</rss>La correspondance des champs pour cet exemple de media RSS se trouve ici.
Définir la correspondance des champs
Définissez la correspondance entre les zones du fichier d'importation et les champs de la liste Selligent.
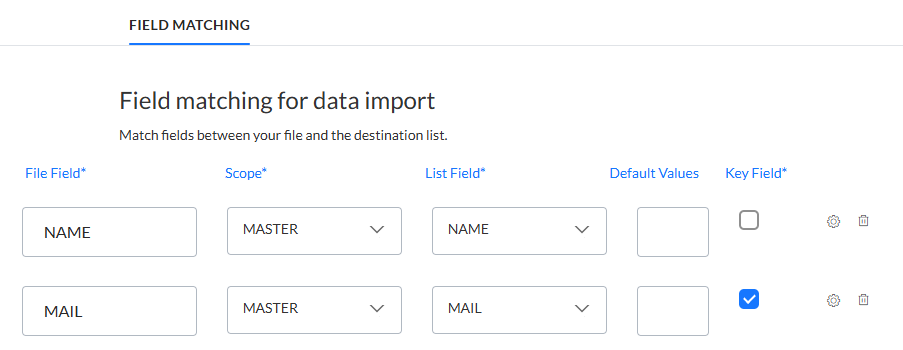
Champ Fichier — Entrez le nom du fichier dans le fichier d'importation.
Scope — Cette colonne n'est disponible que lors de l'importation dans une liste d'audiences. Cela permet d'importer vers des listes 1:1 liées pour l'audience sélectionnée. Sélectionnez l'audience 1:1 liée dans laquelle les données du fichier source doivent être importées.
Remarque: Quand l'option Supprimer les fiches existantes est sélectionnée dans les propriétés d'importation, il est impossible d'effectuer une importation dans la liste liée 1:1.
En outre, si vous effectuez une importation dans une liste liée 1:1, ces informations sont disponibles dans l'aperçu de l'utilisation de la liste liée. Il n'est pas possible de supprimer cette dernière.
Champ Liste — Sélectionnez un champ dans la liste cible à partir du menu déroulant.
Remarque: Si vous effectuez une importation dans une liste d'événements personnalisés, il est impossible d'importer les valeurs dans le champ État. Il s'agit en effet d'un champ système qui ne peut pas être utilisé durant l'importation.
Default value — The default value attributed to the Selligent field. This default value is used when there is no value in the source field, or when the source field used in the mapping does not exist.
Champ clé — Cochez l'option du champ sélectionné, utilisé comme champ clé. Cette option n'est pas disponible pour les importations dans une liste 1:1 liée.
Remarque : Lorsque le champ ID de la liste cible est utilisé comme champ clé, les fiches peuvent uniquement être mises à jour. Aucune insertion ne sera effectuée.
Pour l'exemple de media RSS mentionné ici, la correspondance des champs peut se présenter comme suit :
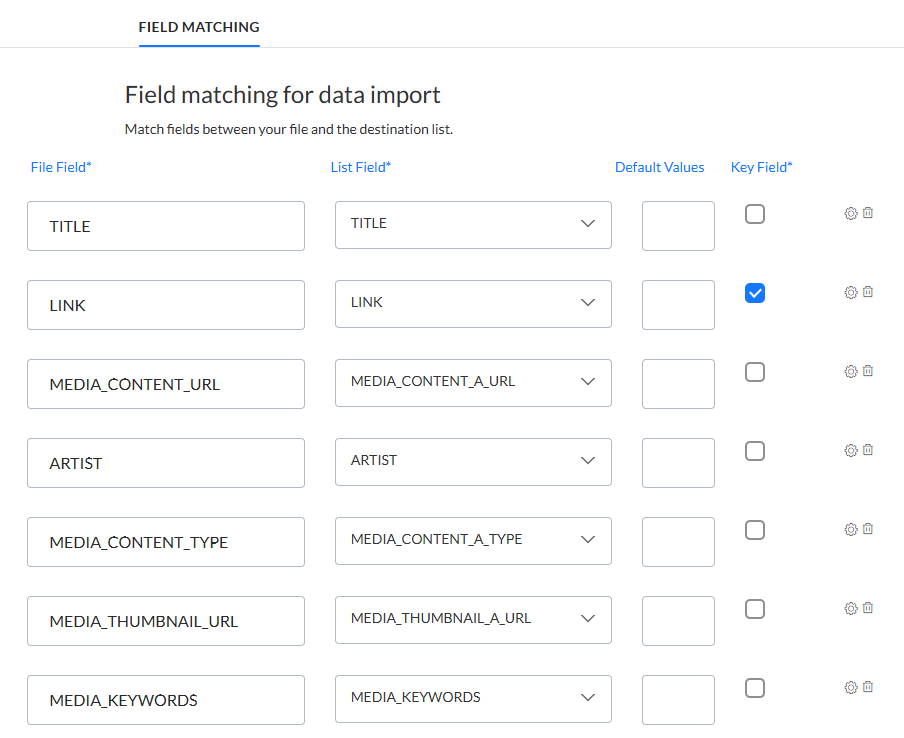
Dans cet exemple, « media:content » et tous ses attributs peuvent être mis en correspondance, mais « media:category » ne peut pas être utilisé pour la mise en correspondance
<?xml version="1.0" ?>
<rss version="2.0">
<channel>
<item>
...
<media:content url="http://www.foo.com/movie.mov" type="video/quicktime">
<media:category type="test">child 1</media:category>
</media:content>
...
</item>
</channel>
</rss>
L'icône en forme d'engrenage permet de définir d'autres options de mappage des champs sélectionnés, en transformant les données dans le fichier source grâce à une recherche inversée dans une liste Selligent. La fonction de recherche inversée peut être utilisée:
- pour les champs liés aux listes d'options, où une valeur du fichier source est remplacée par le code correspondant dans la liste d'options Selligent. Cette fonction est disponible pour les importations dans n'importe quel type de liste, excepté les listes d'options. Exemple : remplacez la valeur « Homme » dans la rubrique Genre du fichier source par le code 100 lors de l'importation des fiches. Remplacez « Femme » par 101.
- Pour les champs des listes d'audiences, des listes de sélection de données, des listes d'événements personnalisés et des listes de données : les valeurs de champs sont remplacées par la clé primaire dans la liste de recherche. Selon le type de liste Selligent pour laquelle l'importation est effectuée, différentes recherches sont possibles :
- Importer dans une liste d'options : Aucune recherche inversée n'est disponible.
- Importer dans la liste de données, liste d'audience et liste d'événements personnalisés: Vous pouvez faire des recherches dans la liste d'options, la liste d'audiences et la liste de sélection de données.
- Importer dans la liste de sélection de données : Vous pouvez faire des recherches de valeurs dans la liste d'options.
Remarque: Quand l'option Supprimer les fiches existantes est sélectionnée dans les propriétés d'importation, il est impossible d'effectuer une recherche inverse. Aucune transformation ne peut être effectuée.
Exemple 1: Remplacez les valeurs du fichier par les codes de la liste d'options
Quand vous importez un fichier avec des contacts dans une liste d'audiences pour laquelle le champ Genre est lié à une liste d'options, vous pouvez remplacer la valeur de genre importée par le code correspondant stocké dans la liste d'options Selligent. Ici, nous utilisons la liste d'audiences « Parana Customers Import », dans laquelle le champ Genre est lié à la liste d'options 'Gender_OptionList'.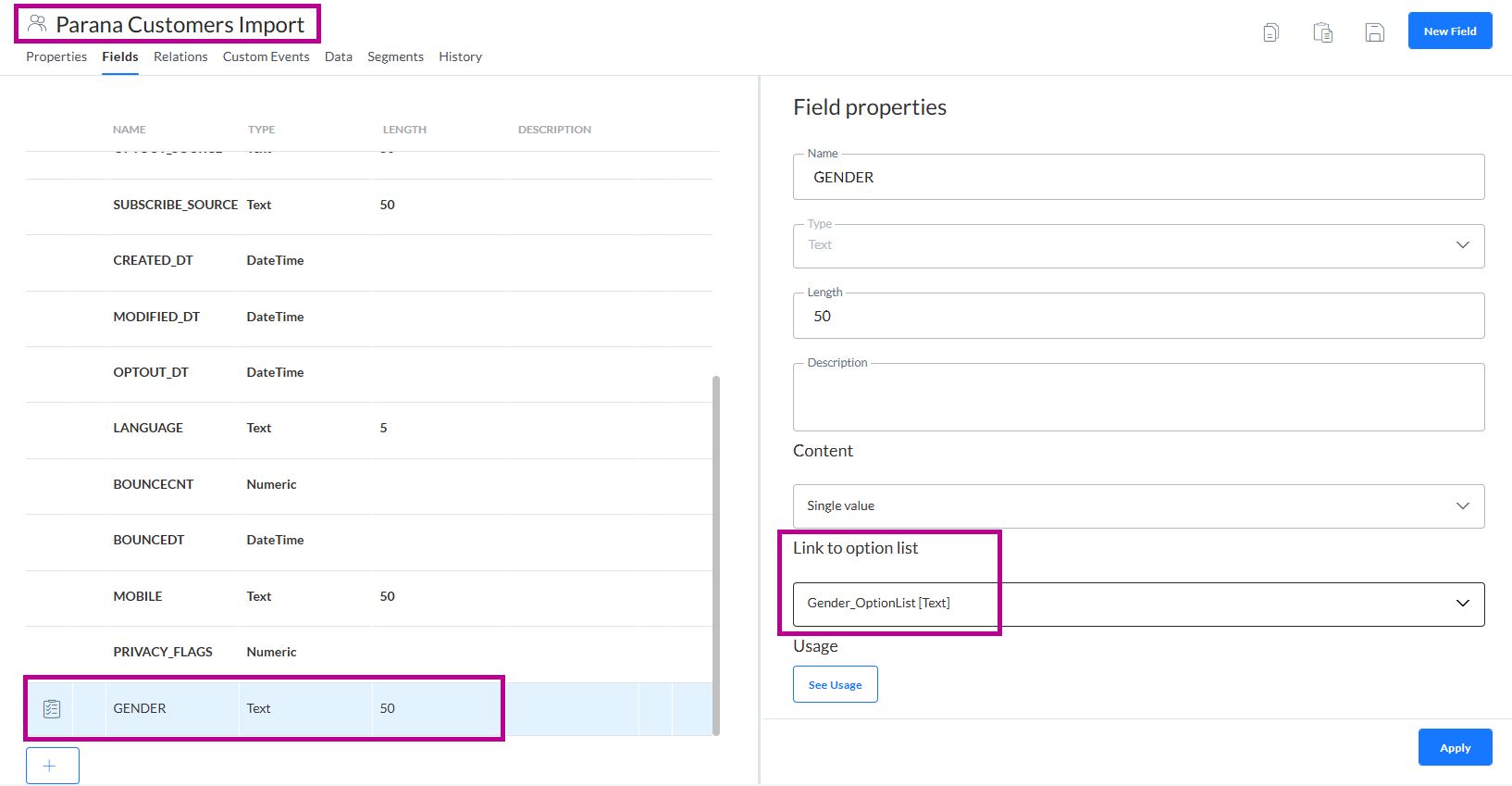
La liste d'options contient les données suivantes :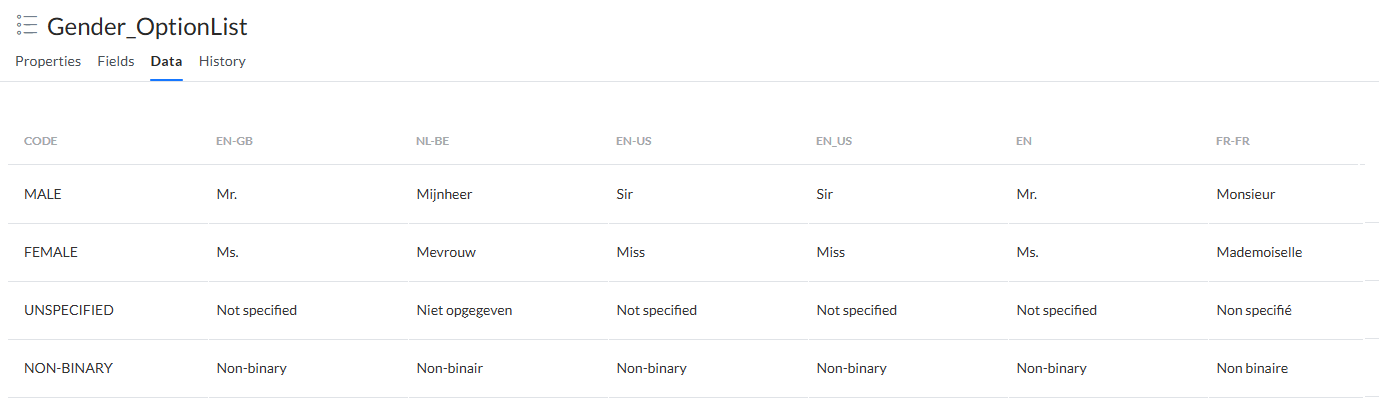
Sur la page Mappage, effectuez une recherche dans la liste d'options Genre afin de récupérer le code. ,
,
En regard du mappage du champ Genre, cliquez sur l'icône en forme d'engrenage et sélectionnez "Recherche inversée - Liste d'options". La liste d'options Selligent est automatiquement remplie. En effet, dans la liste d'audiences Selligent, le champ Genre est lié à la liste d'options ‘Gender_OptionList’. Enfin, sélectionnez une langue à partir du menu déroulant pour vous assurer que la correspondance est basée sur la bonne langue.
Remarque : cela implique que les informations du fichier source soient toujours disponibles dans la langue 1. Par conséquent, une recherche est effectuée dans la liste d'options Selligent afin de faire correspondre la valeur dans le champ de fichier à une valeur dans une langue spécifique de la liste d'options. Ensuite, le code correspondant est renvoyé et stocké à la place de la valeur originale.
Exemple 2: Remplacez les ID externes par les clés primaires Selligent.
Importation dans une liste de données et remplacement de l'identifiant externe K_USERID par l'identifiant unique stocké dans la liste d'audiences « CONTACTPROFILE ».
Pour cela, nous devons effectuer une recherche inversée dans la liste d'audiences. La configuration s'affiche comme suit: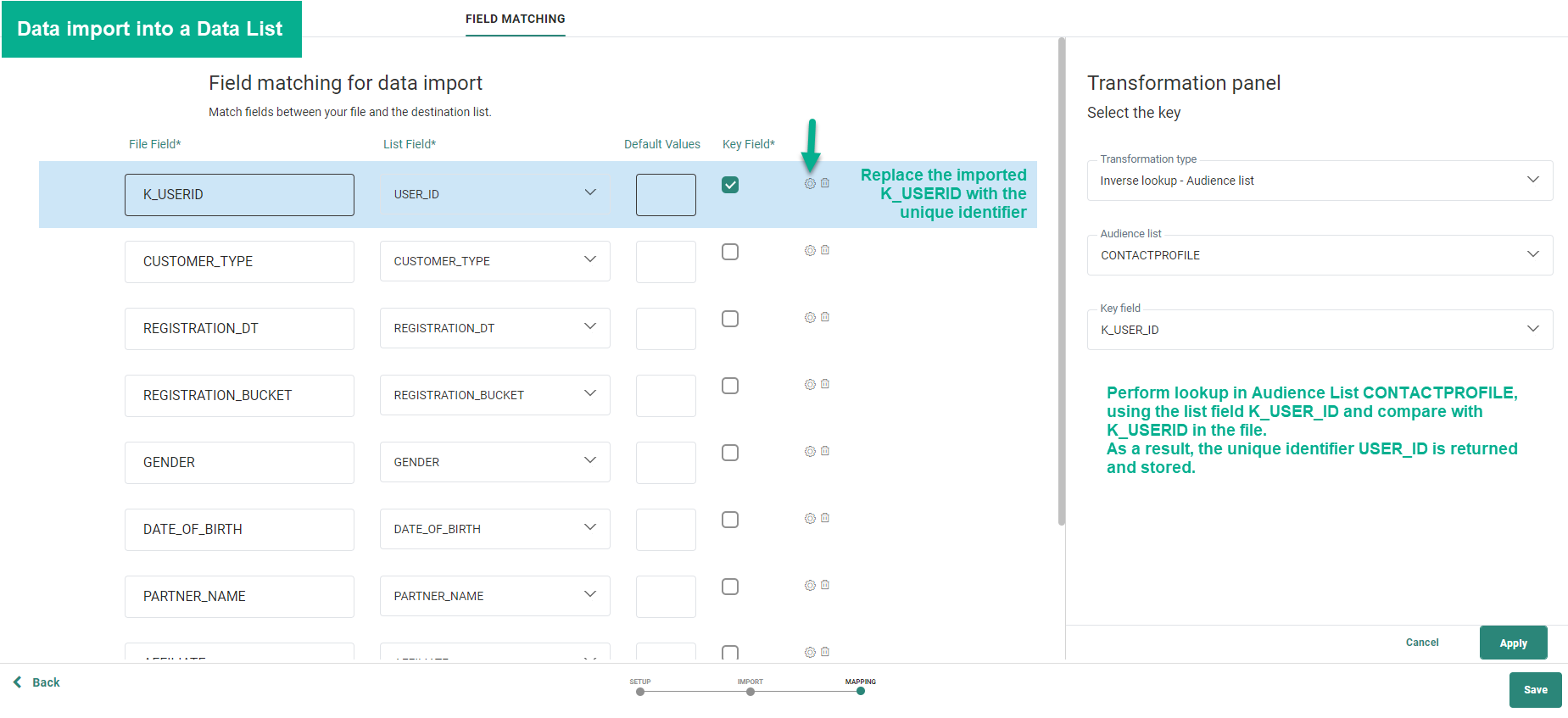
En fonction de la correspondance entre le champ de fichier K_USERID et le champ de liste d'audiences K_USER_ID, l'ID unique USERID peut être récupéré afin de remplacer l'ID externe et de le stocker dans la liste de données au moment de l'importation dans la liste.
Ajoutez autant de champs que nécessaire. Chaque fois qu'une correspondance est définie, une nouvelle ligne est automatiquement ajoutée à la table de correspondance.
Remarque: Si vous effectuez une recherche inverse dans une liste de sélection de données en vue de transformer les données de fichier entrantes en valeur Selligent, vous pouvez définir le champ Fichier comme facultatif pour la validation. Si cette option est définie, même lorsque la valeur de recherche est détectée pour la valeur du champ, la fiche est toujours mise à jour et seule la mise à jour du champ est ignorée.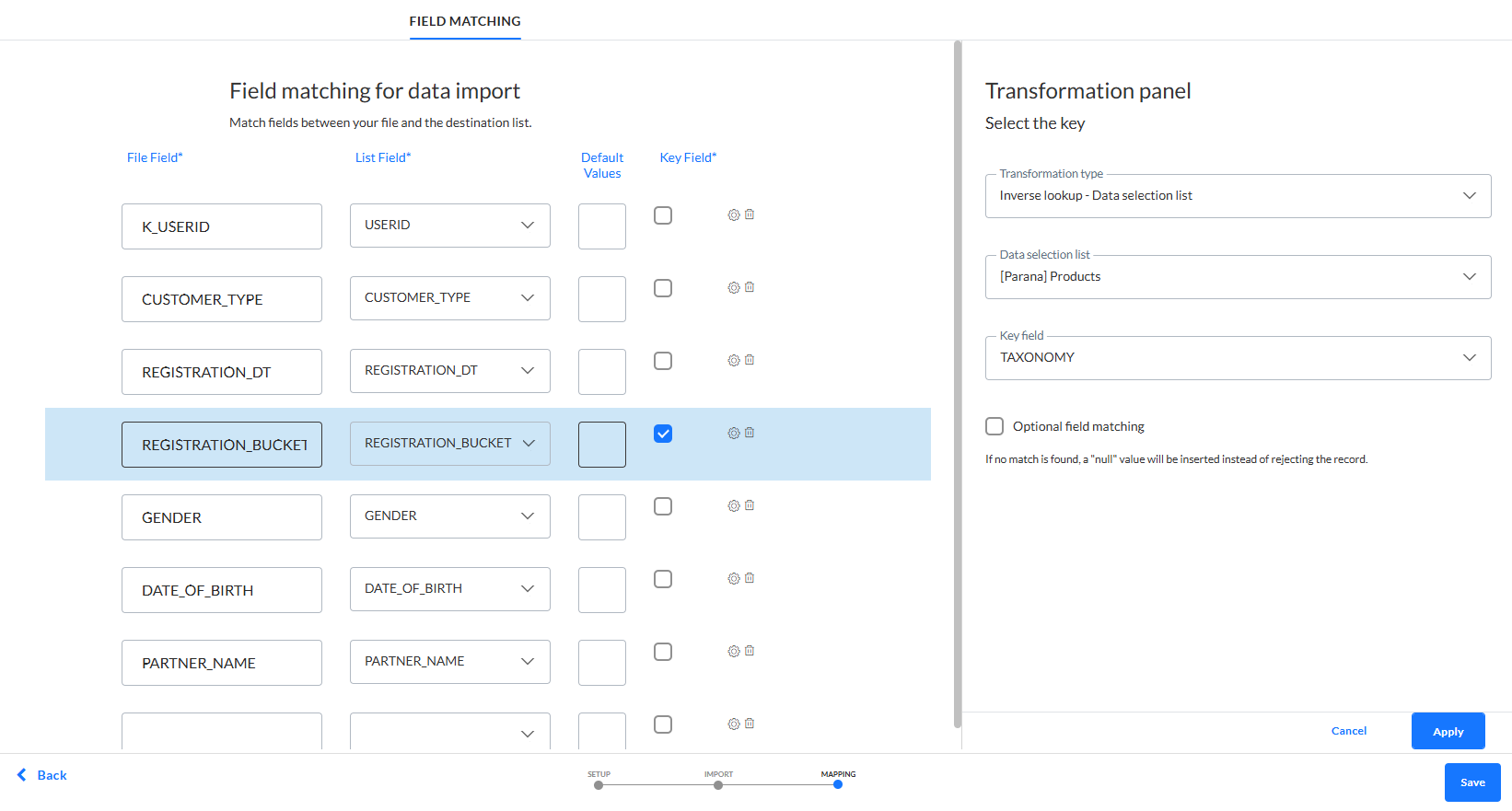
Lorsque vous avez terminé, cliquez sur Enregistrer. L'importation de données est ajoutée à la page de démarrage.
Historique
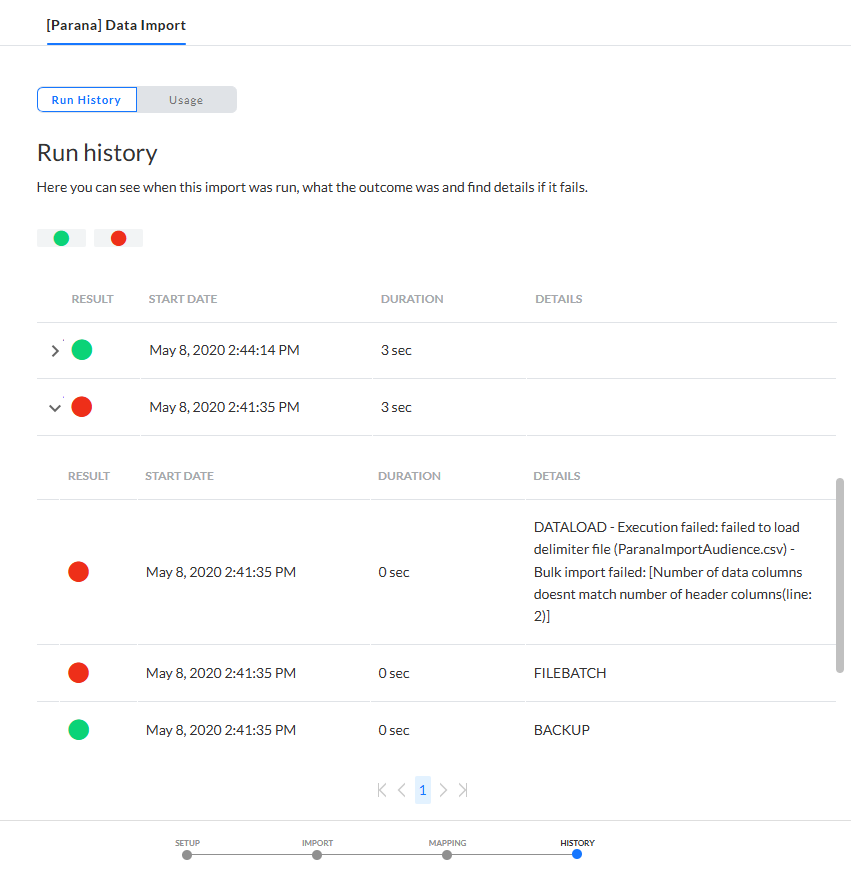
Une fois l'importation configurée, un onglet Historique fournit des détails sur l'exécution de l'importation, la durée et la date de début. Il apporte des précisions en cas d'erreur. Ces informations sont disponibles dans l'Historique de l'exécution.
L'onglet Utilisation fournit des informations sur l'endroit où l'importation des données est utilisée.
